Olá, mundo! Meu nome é Vinícius e este é o post de estreia do meu blog, um espaço onde quero desmistificar o universo da Inteligência Artificial, Machine Learning e Deep Learning. E que melhor maneira de começar do que compartilhando a história do meu primeiro projeto completo?
Não vou apresentar um tutorial perfeito com resultados mágicos. Pelo contrário, quero compartilhar a jornada real, com os becos sem saída, as descobertas inesperadas e a emoção de, finalmente, fazer a coisa funcionar. A história de hoje é sobre como um modelo com 62% de acurácia, que parecia um fracasso, se tornou um sistema de 74%, funcional e inteligente.
Vamos lá?
O Desafio: Entendendo Sentimentos em Textos
O objetivo era claro: construir um modelo de Machine Learning capaz de ler um texto curto (como um post de rede social) e classificá-lo como Positivo, Negativo ou Neutro. Uma tarefa clássica de Análise de Sentimentos.
Passo 1: A Análise Exploratória — A Fundação de Tudo
Antes de escrever uma única linha de código de Machine Learning, a primeira e mais crucial etapa é conhecer seus dados. Na Análise Exploratória de Dados (EDA), descobri alguns pontos-chave:
- Simplificação é Poder: O dataset original tinha dezenas de sentimentos. Agrupei-os nas três categorias principais, o que tornou o problema mais gerenciável.
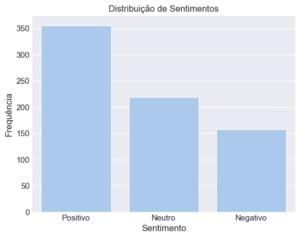
- A Descoberta Crítica (Foreshadowing!): Ao plotar a distribuição das classes, notei algo importante: o dataset era desbalanceado. Quase 50% dos textos eram “Positivos”, enquanto “Negativos” e “Neutros” dividiam o resto. Guarde essa informação.
- Ruído Visual: Criei nuvens de palavras para entender os termos mais comuns em cada categoria. Isso não só me deu uma ideia do vocabulário, mas também revelou “ruídos” — palavras como “like” que apareciam com frequência, mas sem carregar muito sentimento. Decidi que precisaria removê-las no pré-processamento.
Passo 2: A Primeira Tentativa e a Decepção do “Modelo Preguiçoso”
Com os dados limpos e um pipeline de pré-processamento definido (incluindo a remoção de stopwords e a lematização), treinei dois modelos clássicos: Regressão Logística e Random Forest.
Executei os testes e… a acurácia foi de ~62%.
Uma reação inicial poderia ser de desânimo. Mas em ciência de dados, um resultado ruim é apenas um sintoma. A verdadeira tarefa é diagnosticar a causa. E o diagnóstico estava no classification_report:
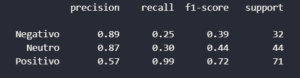
A história que esses números contam é fascinante:
- Recall de “Positivo” era 0.99: O modelo era excelente em encontrar todos os textos positivos.
- Recall de “Negativo” e “Neutro” era baixíssimo (0.25 e 0.30): O modelo era péssimo em encontrar textos dessas classes.
O que aconteceu? O modelo aprendeu a ser preguiçoso. Lembra que nosso dataset era 50% positivo? O modelo percebeu que, na dúvida, a melhor estratégia para maximizar a acurácia era simplesmente chutar “Positivo” na maior parte do tempo. Ele estava acertando muito por pura sorte de volume, mas era incapaz de discernir as nuances das classes minoritárias. Na prática, era um modelo inútil.
Passo 3: A Otimização — Ensinando o Modelo a se Importar
O problema estava claro: o desbalanceamento dos dados. A solução? Fazer o modelo se importar mais com as classes que ele estava ignorando.
A técnica que escolhi foi simples, mas poderosa. Ao treinar os modelos, adicionei um único parâmetro: class_weight=’balanced’.
O que isso faz? Basicamente, ele diz ao algoritmo: “Ei, eu sei que as classes ‘Negativo’ e ‘Neutro’ são raras, mas elas são importantes. Se você errar uma delas, a penalidade será muito maior do que errar na classe ‘Positivo'”.
Isso força o modelo a sair da sua zona de conforto e prestar atenção de verdade aos padrões de todas as classes, não apenas da majoritária.
Passo 4: O Salto — O Nascimento de um Modelo Inteligente
Treinei novamente a Regressão Logística, agora com o parâmetro de balanceamento. O resultado foi um salto espetacular.
A nova acurácia: 74%!
Mas o mais importante não foi o número geral. Foi a mudança no comportamento do modelo:
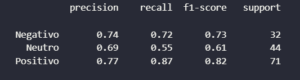
O recall da classe “Negativo” pulou de 0.25 para 0.72 — um aumento de 188%! O modelo não era mais preguiçoso. Ele havia se tornado um sistema equilibrado, capaz de identificar as três categorias com uma competência muito maior.
Conclusão: O Que Aprendi com Meu Primeiro Projeto
Esta jornada reforçou algumas lições fundamentais que, acredito, se aplicam a qualquer projeto de dados:
- Nunca subestime a Análise Exploratória: A pista para o “fracasso” inicial do meu modelo estava lá desde o começo, na distribuição de classes.
- Acurácia nem sempre é a melhor métrica: Um modelo de 62% pode ser pior que um de 50% se ele não estiver aprendendo da maneira correta. Métricas como precision, recall e F1-score por classe contam a verdadeira história.
- Otimizar é mais importante que construir: Passar de um modelo base para um modelo otimizado é onde a mágica realmente acontece. É o que separa um exercício acadêmico de uma ferramenta funcional.
- Abrace os resultados “ruins”: Eles são os melhores professores. São eles que forçam você a investigar, a aprender e a se tornar um profissional melhor.
No final, o projeto foi um sucesso. Não porque alcancei 99% de acurácia, mas porque construí algo realista, funcional e, o mais importante, entendi cada passo do caminho.
Obrigado por me acompanhar nesta primeira jornada! O código completo deste projeto está disponível no meu GitHub.